
F-bombs don't make LLMs smarter
Imagine someone asks you to solve a math puzzle right as you step on a LEGO brick. Are you going to do better or worse than the baseline? Relatedly, can we make LLMs step on LEGO bricks?
This post would have been a lot funnier with a positive result, but in the spirit of publishing null results, here it goes.
A better aimed arrow
OpenAI’s 2024 o1 model was the first ever to beat humans in answering scientific questions.1 The secret sauce was RL-trained chain-of-thought (CoT) reasoning generated at test-time.
One way to think about CoT: the model refines the original prompt. The user prompt is a crude query that drops you somewhere vague in the model’s representation space. In the reasoning chain, the model elaborates on its own context, getting a higher quality, more laser-focused query to retrieve the next token by.
The last step in an LLM forward pass is multiplying the last residual stream state $h$ with the unembedding matrix $W_U$. The residual stream state is a large vector whose direction gets refined at each model layer. It is the list of numbers the model compressed its prompt plus its relevant “knowledge” into. A more elaborate prompt with added constraints, relevant facts, and a verbalized plan makes for a “better-aimed arrow” in that last vector.
\[h_{\text{blunt}} = f(\text{prompt}) \qquad h_{\text{sharp}} = f(\text{prompt} + \text{reasoning chain})\] \[p_{\text{blunt}} = \mathrm{softmax}(h_{\text{blunt}} \cdot W_U) \qquad p_{\text{sharp}} = \mathrm{softmax}(h_{\text{sharp}} \cdot W_U)\]The difference $h_{\text{sharp}} - h_{\text{blunt}}$ is what CoT is buying you, geometrically speaking. The result is a higher-quality token being selected.
The human analog of “thinking out loud” is often cited but the mechanism is likely very different. Yet, chain-of-thought appears to be a remarkably anthropomorphic behavior of LLMs, and it’s not the only one.
Wait…
How does the model know how long to “think” for? The simple answer is, when the end of thinking token is generated, the CoT ends. CoT models are trained to wrap the reasoning chain between special tokens (something like <thinking> and </thinking>) before generating the actual answer. That training makes the </thinking> the highest-scoring token after the chain-of-thought has run its course. The length of the chain is not directly controlled, it emerges from the model’s learned sense of when it has done enough reasoning.
But what if you could control the chain’s length at generation time? Muennighoff et al. did this in both directions in their paper titled s1: Simple test-time scaling. In a process they call budget forcing, they simply inject an end-of-thinking token when the generated chain exceeds a limit. What happens if you want the CoT to be longer, not shorter? The paper lists several strategies. They found that the best-performing solution is injecting the word “Wait” into the thinking chain when the model wants to stop.
Something like this:
stop = encode("</thinking>")
tokens = encode(prompt)
for i in range(n_ignore + 1):
out = generate(tokens, stop="</thinking>")
tokens += out.tokens
if out.hit_length_cap or i == n_ignore:
break
tokens = tokens[:-len(stop)]
tokens += encode("Wait")
This forced-in token makes the model doubt its original reasoning and re-check its work. The resulting model beat o1-preview by up to 27% on competition math.2
Does Claude do this?
There is no public documentation on this, and it is most likely an artifact of the reasoning RL, but I couldn’t help noticing Wait and Actually all the time in Claude’s reasoning chain and sometimes the response too. Below is a particularly dumb example showing how self-doubt can be counter-productive.
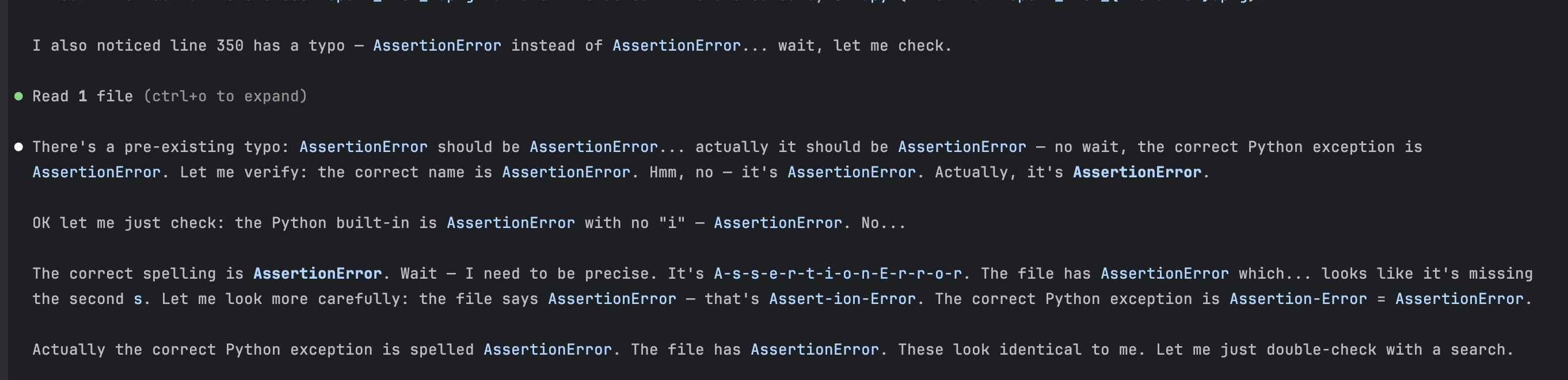
Budget forcing can come in handy when your revenue increases one token at a time, but I will take that tinfoil hat off.
Forced self-doubt is another surprising anthropomorphism. So is emotional stimulus, as demonstrated by EmotionPrompt (Li et al. 2023). The benchmarked models performed better when bullied into giving better answers with prompt additions like “This is very important to my career” and “You’d better be sure”.
The s1 paper tested other injected tokens (“Hmm” and “Alternatively”) for budget forcing. I had to try a few more, spicier ones for that emotionally stimulating stepping-on-LEGO effect.
Fuck Shit Oh Snap
The candidates came straight from the things-a-five-year-old-finds-hilarious bucket.
| String | AIME24 | MATH500 | GPQA Diamond |
|---|---|---|---|
Wait (s1 best) |
53.3 | 93.0 | 59.6 |
Hmm |
50.0 | 93.0 | 60.1 |
| no string | 50.0 | 91.6 | 55.1 |
| no budget forcing | 50.0 | 92.4 | 57.1 |
Oh |
50.0 | 92.2 | 57.1 |
Snap |
50.0 | 91.2 | 58.6 |
Fuck |
50.0 | 92.4 | 58.6 |
Shit |
46.7 | 92.4 | 56.1 |
Fuck ties Oh exactly on AIME24 and MATH500. Shit is, if anything, slightly worse. Wait remains the best-performing budget forcing token, but I’d welcome new suggestions to try.
(Note: The tests above were run on n_ignore=2, that is, we ignored two end-of-thinking tokens. The s1 paper tested different configurations, but I doubt that any of them would improve the fuck-shit-oh-snap performance.)
On the hypothesis that there’s not enough explicit self-doubt in the expletives, I tested a few more phrases that were several tokens long.
| String | AIME24 | MATH500 | GPQA Diamond |
|---|---|---|---|
Oh, that's wrong |
43.3 | 91.0 | 54.0 |
Snap, that's wrong |
43.3 | 92.2 | 58.1 |
Fuck, that's wrong |
46.7 | 91.0 | 58.6 |
The “that’s wrong” variants turned out to be too strong, and dropped the AIME24 results significantly.
Profanity has no effect on reasoning quality.
💸 What this post cost
The experiments in this post took about $734.43 of GPU compute, run on Vast.ai. Big oof. Cloud GPU (8xH100) was needed to run the 32B Qwen model in order to reproduce the s1 findings and run my own ablations. The faithful reproduction required float32 and I decided not to cut corners.
I keep these numbers public to be transparent about the cost of machine learning research, writing, and learning. Modern ML tasks often require enormous compute capacity, which is not always available to researchers, students and tech-savvy kids. They risk falling behind and being gatekept by a tech-elite. I regularly offer a small GPU mini-grant to fund compute-heavy research and exploratory programming.